
Tutorial: Running linear mixed effects models#
This lab delves into mixed-effects models and their implementation in R.
Goals:#
Learn how to use the
lmer()function
This tutorial draws from Chapter 1 in Bates, D., Maechler, M., Bolker, B., & Walker, S. (2014). “lme4: Linear mixed-effects models using Eigen and S4”. R package version:, 1(7), 1-23.
Linear mixed-effects models#
Linear mixed-effects models let you account for correlations among your observations and variation due to variables other than those of interest (like participant or classroom). Let’s see how we can use the linear mixed-effects tools in R.
To get started, we will need to install the lme4 library in R.
# Load LME4
# install.packages("lme4") # Uncomment if not installed.
library(lme4)
library(ggplot2)
This library includes a sleep study experiment that we will use to practice fitting a mixed-effect model.
#help(sleepstudy) # Uncomment to see documentation
head(sleepstudy)
| Reaction | Days | Subject | |
|---|---|---|---|
| <dbl> | <dbl> | <fct> | |
| 1 | 249.5600 | 0 | 308 |
| 2 | 258.7047 | 1 | 308 |
| 3 | 250.8006 | 2 | 308 |
| 4 | 321.4398 | 3 | 308 |
| 5 | 356.8519 | 4 | 308 |
| 6 | 414.6901 | 5 | 308 |
The documentation summarizes these data:
“The average reaction time per day for subjects in a sleep deprivation study. On day 0 the subjects had their normal amount of sleep. Starting that night they were restricted to 3 hours of sleep per night. The observations represent the average reaction time on a series of tests given each day to each subject.”
So we have a data frame with 180 observations on the following 3 variables.
Reaction: Average reaction time (ms)
Days: Number of days of sleep deprivation
Subject: Subject number on which the observation was made.
The main question we have here is whether days of consecutive sleep deprivation impact reaction times. This boils down to a repeated measures problem: the same subjects are tested across multiple days, so random effects associated with each individual will also carry over across days, violating the assumption that each observation is independent and identically distributed (i.e., iid).
Let’s take a look at the fixed effects. Below, we plot the data by days and then grouped by subject/
ggplot(sleepstudy, aes(Days, Reaction, color = Subject)) +
geom_point() + geom_smooth(method="lm",se=FALSE)
`geom_smooth()` using formula = 'y ~ x'
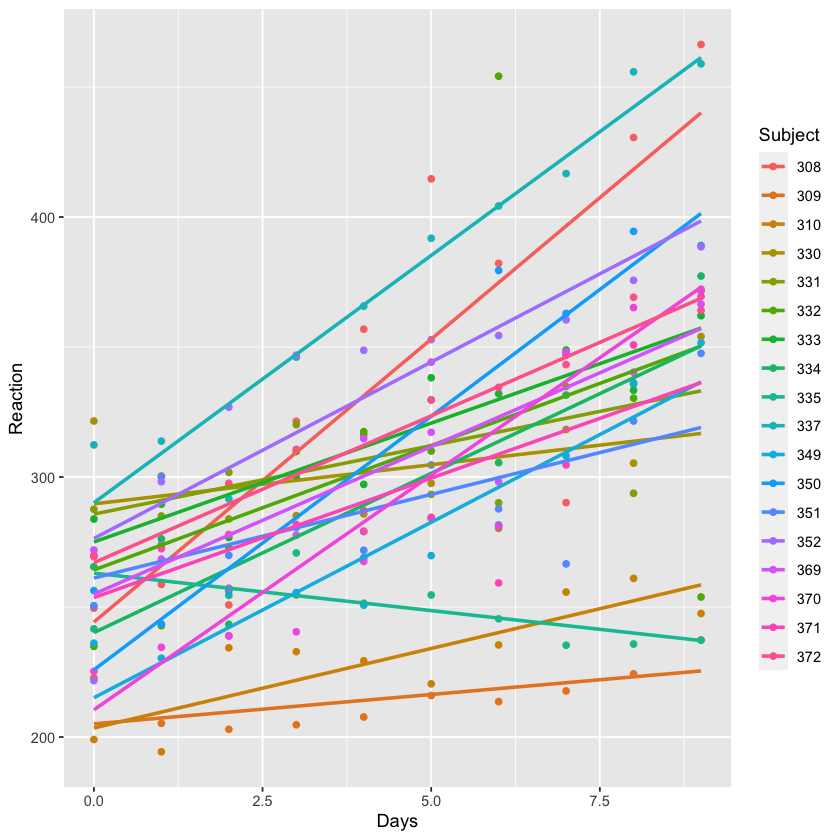
Note that not only do individual subjects’ baseline RTs differ (i.e., their intercepts), but the rates at which their RTs change with days of little sleep differ (i.e., their slopes). Put another way: subjects have different reaction speeds, and they’re also differently affected by lack of sleep.
Tangent: I knew a guy who was like subject 335 once. He seemed to thrive on lack of sleep.
Let’s see what happens if we try to fit a regular linear model to these clustered data.
fe.fit = lm(Reaction~Days, data=sleepstudy)
summary(fe.fit)
Call:
lm(formula = Reaction ~ Days, data = sleepstudy)
Residuals:
Min 1Q Median 3Q Max
-110.848 -27.483 1.546 26.142 139.953
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 251.405 6.610 38.033 < 2e-16 ***
Days 10.467 1.238 8.454 9.89e-15 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 47.71 on 178 degrees of freedom
Multiple R-squared: 0.2865, Adjusted R-squared: 0.2825
F-statistic: 71.46 on 1 and 178 DF, p-value: 9.894e-15
Even though we’re ignoring the role of subjects in the example above, we still get a significant effect of days of sleep deprivation on reaction time. But because we haven’t accounted for the clustered data, the estimate and standard error here are actually incorrect.
To account for the subject effects, let’s treat them as a random effect. In this case we will assume that the effect of sleep deprivation on reaction times varies by subject.
In lmer, random-effects terms are distinguished by vertical bars (|) separating expressions for design matrices from grouping factors.
Some notes on usage for the random effects terms:
If you just want to find the random intercepts (i.e., you care about subject differences in starting reaction times but not about how each subjects’ RTs change as
Daysincreases), then write the random effects term as(1 | Subject).If you want both random intercepts and random slopes, you can write either
(1+Days | Subject)or(Days | Subject). In the second case, the “1+” is inferred since usually if the analyst wants slopes they also want intercepts.If you want just random slopes, you can write
(0+Days | Subject).
Given the plot above, I think we need to care about both intercepts and slopes. But to be sure, let’s try it both ways.
# Random intercepts and slopes across subjects
me.fit1 = lmer(Reaction ~ Days + (Days | Subject), data=sleepstudy)
# ^^ the same as me.fit1 = lmer(Reaction ~ Days + (1+Days | Subject), data=sleepstudy)
# Random intercepts only
me.fit2 = lmer(Reaction ~ Days + (1 | Subject), data=sleepstudy)
print("*******me.fit1********")
summary(me.fit1)
print("*******me.fit2********")
summary(me.fit2)
[1] "*******me.fit1********"
Linear mixed model fit by REML ['lmerMod']
Formula: Reaction ~ Days + (Days | Subject)
Data: sleepstudy
REML criterion at convergence: 1743.6
Scaled residuals:
Min 1Q Median 3Q Max
-3.9536 -0.4634 0.0231 0.4634 5.1793
Random effects:
Groups Name Variance Std.Dev. Corr
Subject (Intercept) 612.10 24.741
Days 35.07 5.922 0.07
Residual 654.94 25.592
Number of obs: 180, groups: Subject, 18
Fixed effects:
Estimate Std. Error t value
(Intercept) 251.405 6.825 36.838
Days 10.467 1.546 6.771
Correlation of Fixed Effects:
(Intr)
Days -0.138
[1] "*******me.fit2********"
Linear mixed model fit by REML ['lmerMod']
Formula: Reaction ~ Days + (1 | Subject)
Data: sleepstudy
REML criterion at convergence: 1786.5
Scaled residuals:
Min 1Q Median 3Q Max
-3.2257 -0.5529 0.0109 0.5188 4.2506
Random effects:
Groups Name Variance Std.Dev.
Subject (Intercept) 1378.2 37.12
Residual 960.5 30.99
Number of obs: 180, groups: Subject, 18
Fixed effects:
Estimate Std. Error t value
(Intercept) 251.4051 9.7467 25.79
Days 10.4673 0.8042 13.02
Correlation of Fixed Effects:
(Intr)
Days -0.371
If we look at the t-value for Days on Reaction in the Fixed effects of me.fit1, it has dropped to 6.77 (from 8.45 in the simple linear model). Thus we are getting a more conservative model fit on the fixed effects.
Notice that the report on the random effects doesn’t provide an inferential statistic (i.e., a t-value). Interpreting the magnitude of a random effect depends on domain-specific information rather than null hypothesis testing (also remember that variance can’t be negative, so the distribution is bounded at 0 – so variance terms will always be “statistically significant”, but may not represent meaningful variance across participants). Here, we are not looking for how variability in individuals changes the effect of sleep loss over time or at individual differences in the baseline reaction times (you need more complex models to include random effects as predictors). Instead, we are trying to estimate the fixed effects, taking into account this random variation. lmer provides a t-value for fixed effects, but not a p-value. You don’t need a p-value for interpretation, but if want it (e.g., for publication requirements) you can use the lmerTest package.
To interpret the value of including the random effects term in your model, you will want to do a model comparison. Specifically, you might want to test whether the mixed-effect model provides a better fit to the data than the simple linear regression model.
Remember the bias-variance tradeoff, and how a more complex model will generally provide a better fit? These three models have different model complexities, so you’ll have to use an evaluation criterion that takes complexity into account (e.g., AIC). For now you can think of the AIC as quanitifying the amount of information lost or the variance unexplained (so a lower score would be better).
# We will compare the two models using the Akaike information criterion (AIC)
ic = AIC(fe.fit, me.fit1, me.fit2)
ic
diff(ic$AIC)
| df | AIC | |
|---|---|---|
| <dbl> | <dbl> | |
| fe.fit | 3 | 1906.293 |
| me.fit1 | 6 | 1755.628 |
| me.fit2 | 4 | 1794.465 |
- -150.664784396412
- 38.8368134349694
As you might have expected, me.fit1 has the lowest AIC, and so seems to be the best model choice for the data. The difference in AIC between fe.fit and the other two models is quite big, which means that the mixed-effects models account for substantially more variance in reaction time than the simple linear model, even after accounting for increased complexity.
Notebook authored by Ven Popov, and edited by Krista Bond, Charles Wu, Patience Stevens, Amy Sentis, and Fiona Horner.