
Tutorial: Implementing cross validation#
This lab focuses on how to implement cross-validation methods in R.
Goals:#
Understand the limitations of the simple validation set approach, and the benefits of more refined approaches
Learn to use the
cv.glm()function to implement:leave-one-out cross-validation (LOOCV)
k-fold cross-validation (k-fold CV)
Understand the bias-variance trade-off in the context of these resampling methods
This lab draws from the practice sets at the end of Chapter 5 in James, G., Witten, D., Hastie, T., & Tibshirani, R. (2013). “An introduction to statistical learning: with applications in r.”
Why not use the simple validation set approach?#
Up until now, when we’ve wanted to “train” a model and then “test” it (such as in our demos of KNN in the previous tutorial), we’ve chosen a subset of the dataset to be test observations and then trained on the remainder. Although this is relatively simple and easy to implement, there are significant drawbacks to this method:
The validation estimate of the test error rate can be highly variable
Only a subset of observations (those in the training set) are used to train the model
This limits the statistical power, and may lead to overestimating test error rate
Cross-validation, a resampling method used to partition your data into test and training sets, addresses both of these issues.
Let’s see how this is true.
Validation data sets#
Here we will explore test error rates using cross-validation. We’ll be using the Auto data set again from the ISLR library.
First, we should acknowledge that you’ll need to reset the seed for your random number generator. For this use the set.seed() function. We want to use the same seed as the book so that you get the same results.
install.packages("ISLR")
library(ISLR)
library(tidyverse)
set.seed(1) #set the seed for the random number generator. resetting the seed will give different results.
train = sample(x = 392, size = 196) # sample 196 indices from the vector 1:392
Installing package into ‘/usr/local/lib/R/site-library’
(as ‘lib’ is unspecified)
Above we choose 196 unique random samples out of a list ranging from 1-392. These indices will identify our training set.
ggplot(Auto,aes(mpg,horsepower)) + geom_point()
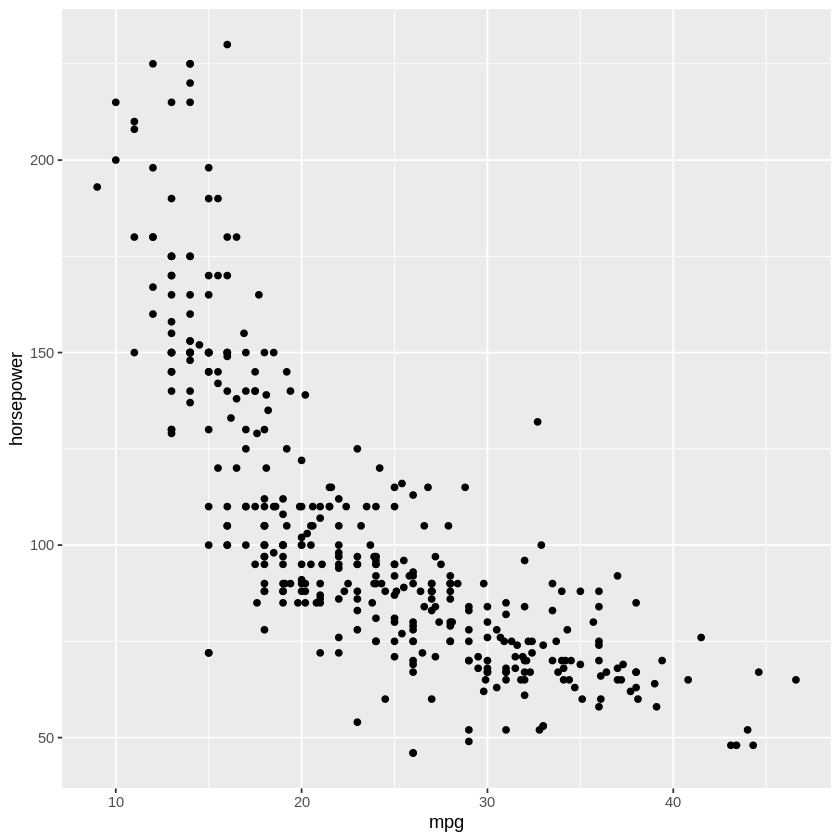
Now let’s fit some models doing the training-testing approach that we’ve used so far in this class.
# Generate a linear model using the training subset
lm.fit = lm(mpg~horsepower, data=Auto, subset=train)
mean((Auto$mpg-predict(lm.fit,Auto))[-train]^2) # Mean Squared Error (MSE) for test set
# Use the poly() function to estimate test error
# for polynomial and cubic regressions
# 2nd degree polynomial
lm.fit2 = lm(Auto$mpg~poly(horsepower,4), data=Auto, subset=train)
mean((Auto$mpg-predict(lm.fit2,Auto))[-train]^2) # Mean Squared Error (MSE) for test set
# 3rd degree polynomial
lm.fit3 = lm(Auto$mpg~poly(horsepower,6), data=Auto, subset=train)
mean((Auto$mpg-predict(lm.fit3,Auto))[-train]^2)
So the MSE we observe for the linear and the two polynomial models (quadratic & cubic) is 23.27, 19.16, and 19.59 respectively. But these exact values are sensitive to the particular subset we selected. Let’s repeat this selecting a different subset of the Auto data.
# Notice that if we use a different subsample we'd get different results
set.seed(2) #using a different seed
train = sample(392, 196)
# Linear model
lm.fit = lm(mpg~horsepower, data=Auto, subset=train)
mean((Auto$mpg-predict(lm.fit,Auto))[-train]^2)
# Polynomial
lm.fit2 = lm(mpg~poly(horsepower,4), data=Auto, subset=train)
mean((Auto$mpg-predict(lm.fit2,Auto))[-train]^2)
# Cubic
lm.fit3 = lm(mpg~poly(horsepower,6), data=Auto, subset=train)
mean((Auto$mpg-predict(lm.fit3,Auto))[-train]^2)
This is a smaller demonstration of what is shown in figure 5.2 of James, G., Witten, D., Hastie, T., & Tibshirani, R. (2013). “An introduction to statistical learning: with applications in r.”. Depending on the specific training set we use, the test error estimate can vary substantially.
Leave-one-out cross-validation (LOOCV)#
Leave-one-out cross-validation (LOOCV) repeatedly splits the set of \(n\) data points into a training set that has all except one observation, and a validation set that has only a single observation. The test error is estimated by averaging the \(n\) resulting MSEs. Below, the first training set contains everything except observation 1, the second training set contains everything except observation 2, and this continues until \(n\) training sets are created and tested.
The boot library in R has many tools to perform LOOCV using a model fit object. Let’s try performing LOOCV using the glm() function and the cv.glm() function.
We’ll start with a simple linear regression model predicting mpg from horsepower, using the full data set.
# Continue with the Auto example
glm.fit = glm(mpg~horsepower, data=Auto)
coef(glm.fit)
- (Intercept)
- 39.9358610211705
- horsepower
- -0.157844733353654
Now let’s use LOOCV, via the cv.glm() function, to estimate the cross validated MSE per the following equation.
library(boot) # Load the bootstrap library
#?cv.glm() #uncomment to get more information about this function
#run LOOCV by setting k to the number of observations
cv.err = cv.glm(Auto, glm.fit, K=nrow(Auto))
cv.err$delta
- 24.2315135179292
- 24.2311440937561
Note that if you don’t define k in the cv.glm function, the default is LOOCV. So an equivalent way to run the above model is:
#if you don't define k in the cv.glm() function, the default is LOOCV
cv.err = cv.glm(Auto, glm.fit)
cv.err$delta[1]
Also, the default prediction error function for cv.glm() is MSE, but you can change that with “cost” variable if needed. Foreshadowing the exercises for this lesson…
The first entry of cv.err$delta above is the raw cross-validation estimate of prediction error (equation above) and the second is the adjusted cross-validation estimate designed to compensate for the bias introduced by not using leave-one-out cross-validation. The thing is, we did use leave-one-out cross-validation (K=nrow(Auto)), so the two values above are very close. But for smaller values of K (i.e., fewer groupings or folds over which cross-validation is run) the bias is greater and thus the error is also greater. The “corrected” value on the right estimates what the estimated MSE would be if we’d used LOOCV instead. Try changing K to a smaller value to see how the difference between the left and right delta values changes.
As noted in the textbook reading, there are some advantages to the bias introduced using smaller values of K - LOOCV isn’t always the superior method.
Let’s look at LOOCV MSE estimates for polynomial regression (this may take a minute or two to run).
# Repeat for polynomial models up to a factor of 10
# specify your output object - where you'll save the MSE estimates for each poly value
cv.error = rep(0,10)
start.time <- Sys.time()
for (i in 1:10) {
glm.fit=glm(mpg~poly(horsepower,i), data=Auto)
# do LOO crossval for polynomial fits from 1 to 10
cv.error[i] = cv.glm(Auto, glm.fit)$delta[1]
}
end.time <- Sys.time()
# how long did this for-loop take to run?
LOOtime <- end.time-start.time
LOOtime
plot(1:10,cv.error) # plot the error
Time difference of 18.46528 secs
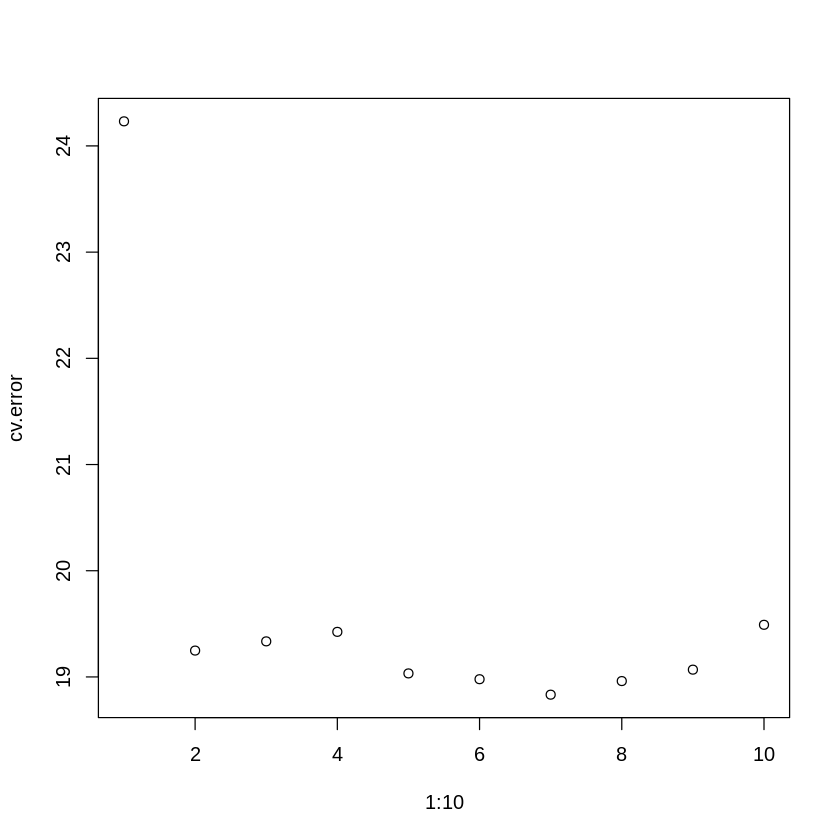
The first entry in the cv.error array is the linear model we estimated above. Notice that we get an initial improvement in accuracy when you move to the 2nd order polynomial, but more complex models (i.e., higher order polynomials) only provide a modest decrease in error. This suggests it would be worth upgrading to a 2nd order polynomial model, but the benefits to increasing the complexity of our model drop off after that. This makes sense when you look at a 2nd order polynomical fit to the data (below) - adding extra bends in the curve won’t improve the error much more. We can trust what the “test” error is telling us about the best model fit more because we used LOOCV instead of the simpler, set-aside-random-test-items approach.
ggplot(Auto,aes(mpg,horsepower)) +
geom_point() +
stat_smooth(method = "lm", formula = y ~ poly(x,2), se = FALSE)
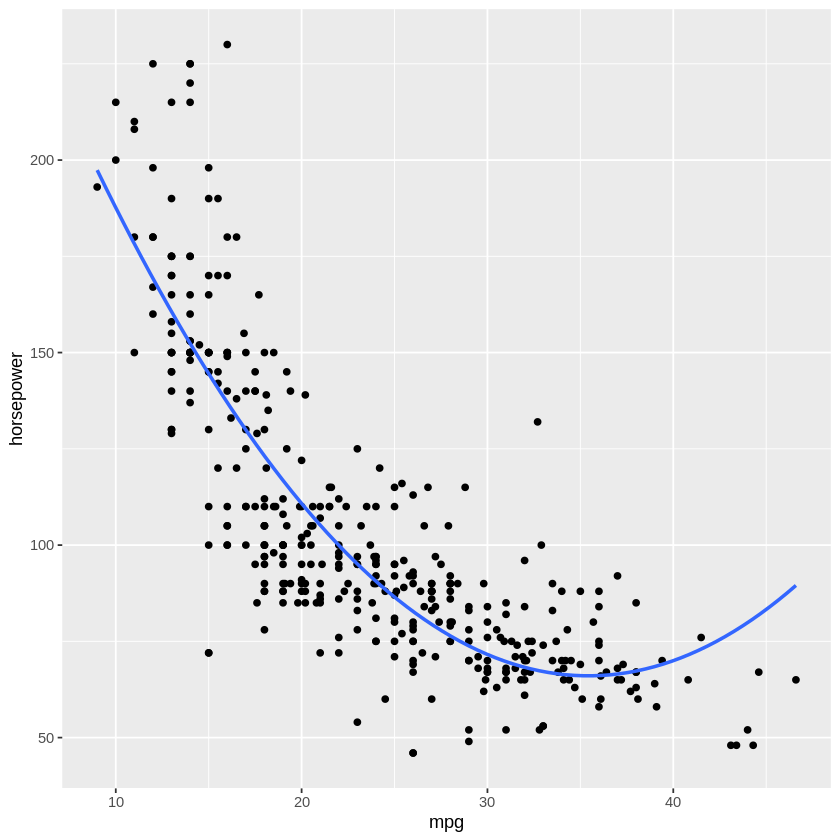
K-fold cross validation#
In k-fold cross validation, the set of \(n\) observations is randomly split into \(k\) unique groups. Each subset of the dataset acts as a validation set, and the remainder is the training set. The average of the \(k\) resulting MSE estimates is the test error.
As stated above, the default k for the cv.glm() function is k=n (i.e., LOOCV). If you don’t want to do LOOCV (if, for example, you have MANY observations and LOOCV would take too long) you can specify the number of folds as an input to the function.
The below code repeates our above loop, but uses k-fold CV instead of LOOVC, where `k = 10’.
# Reset the seed
set.seed(17)
# Always have to specify your output object
cv.error.10 = rep(0,10)
start.time <- Sys.time()
for (i in 1:10){
#get the glm fit for all 10 polynomials
glm.fit=glm(mpg~poly(horsepower,i), data=Auto)
cv.error.10[i] = cv.glm(Auto, glm.fit,K=10)$delta[1]
}
end.time <- Sys.time()
Kfoldtime <- end.time-start.time # how long did this for-loop take to run?
Kfoldtime
Time difference of 0.6577539 secs
We can plot our LOOCV and k-fold results against each other to compare:
plot(cv.error, cv.error.10, xlab="LOOCV error", ylab="10-fold CV error")
lines(c(19,25),c(19,25))
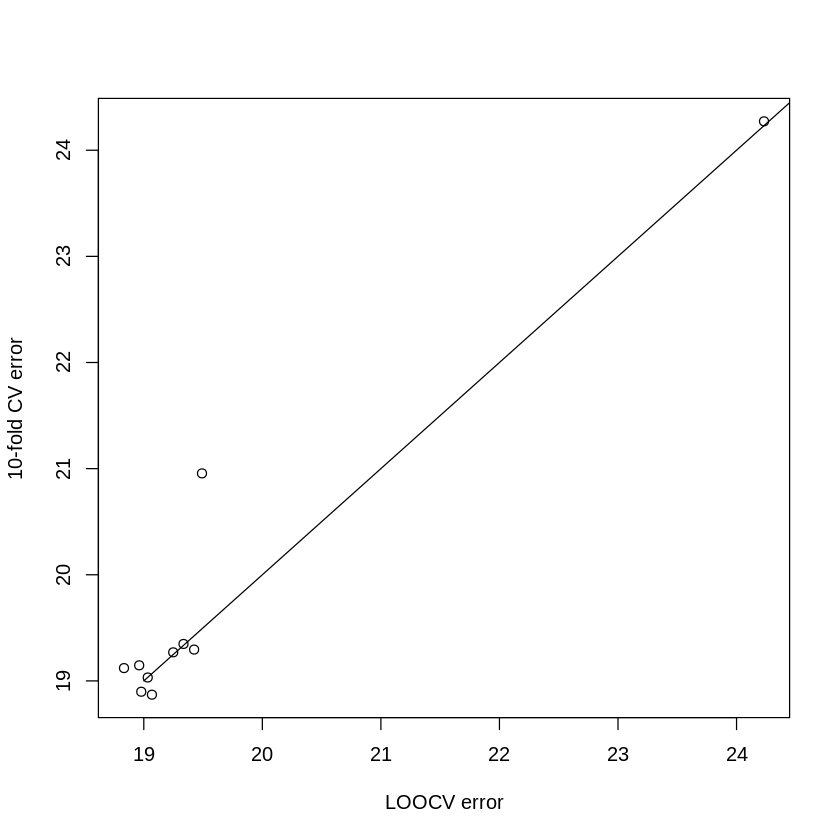
Notice how similar the results are for 10-fold CV & LOOCV. Since we measured how long the leave-one-out and 10-fold methods took to run, we can compare the run times:
print(paste("Leave-one-out runtime:",LOOtime))
print(paste("10-fold runtime:",Kfoldtime))
[1] "Leave-one-out runtime: 18.4652769565582"
[1] "10-fold runtime: 0.657753944396973"
As you can see, 10-fold was much quicker to run.
Notebook authored by Ven Popov and edited by Krista Bond, Charles Wu, Patience Stevens, Amy Sentis, and Fiona Horner.